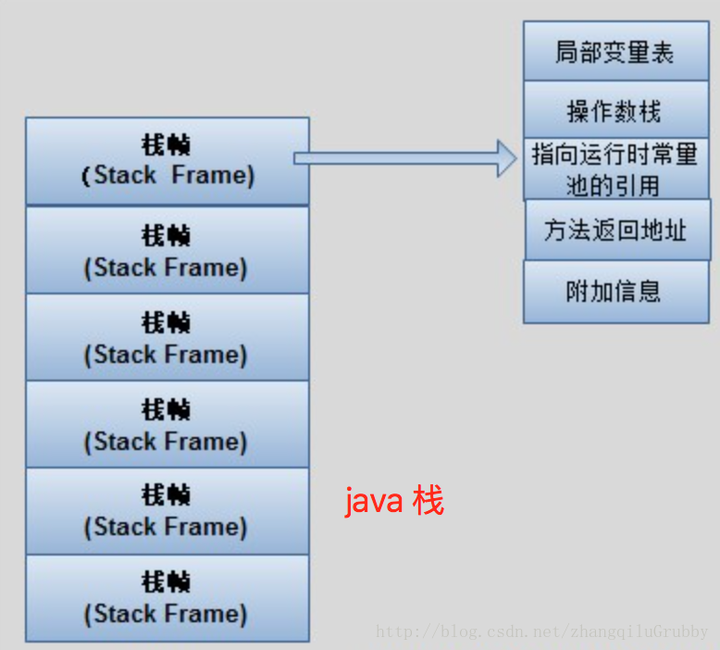
(五)指令系统[计组]
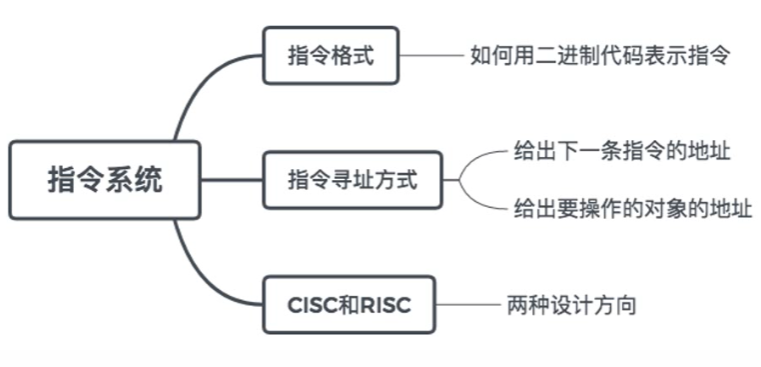
5.1 指令系统概述
5.1.1概述
指令(又称机器指令):是指示计算机执行某种操作的命令,是计算机运行的最小功能单位。
指令系统 : 一台计算机的所有指令的集合,也称为指令集。
注:一台计算机只能执行自己指令系统中的指令,不能执行其他系统的指令。
- 高级语言的语法是通用的, 但是机器语言不同

5.1.2硬件设计过程
 \
\
5.1.3不同层级语言对比
| 语言 | 存储 | 举例 | 特点 |
|---|---|---|---|
| 高级语言 | 硬盘 |  |
C、C++、JAVA , Python等 |
| 汇编语言 | 硬盘 |  |
汇编语言与机器语言一一对应 |
| 机器语言 | 加载到内存中 |  |
不易编写程序, 可读性差 |
机器语言:用指令0/1代码编写程序
汇编语言:用指令助记符编写程序
- 指令助记符:每条指令用英文缩写字母来表示,便于编写程序。
不同的指令集对应不同架构的CPU,也对应不同种类的汇编语言
因此,不同汇编语言编写的程序不能在其他类型的机器上运行:
x86汇编语言有两种语法风格:Intel汇编和AT&T汇编
x86汇编语言分为很多类 , 比如:
- 8086汇编(16位)
- 80x88汇编(也叫BMPC汇编,16位)
- 80x86汇编(x大于3则指32位汇编)
5.1.4指令系统的发展
50年代初期:指令系统只有定点加减、逻辑运算、数据传送、转移等十几至几十条指令。
60年代后期:增加了乘除运算、浮点运算、十进制运算等指令,指令数目多达一二百条,寻址方式也趋多样化。
70年代末期:复杂指令系统(CISC)计算机其指令条数多,格式多样,寻址方式复杂,每条指令的功能强。
优点是汇编程序设计容易些,但控制器的实现困难,许多指令被使用的机会不多。CISC庞大的指令系统不易调试维护,造成硬件资源浪费。为此又提出了精简指令系统(RISC)计算机其指令数目少,格式与功能简单,运行速度快,控制器易实现。
系列兼容机:
基本指令系统相同、基本体系结构相同的一系列机器。一个系列往往有多种型号,在结构和性能上有所差异。新指令系统一定包含旧指令,实现软件兼容,减少重复开发
例如:IBMPC(286/386/486/Pentium) 微机系列等
指令系统是软件生态的起点只有从指令系统的根源上实现自主,才能打破软件生态发展受制于人的锁链。

5.1.5相关概念
数据字:一个存储字表示一个数。
指令字:一个存储字表示一条指令。
机器字长:指计算机一次能直接处理的二进制代码位数;
指令字长:一条指令中包括的二进制代码位数。
半字长指令:指令字长等于半个机器字长的指令:
单字长指令:指令字长等于一个机器字长的指令:
双字长指令:指令字长等于两个机器字长的指令。
定字长指令结构:在一个指令系统中,各种指令字长相等。
变字长指令结构:在一个指令系统中,各种指令字长不相等。

从指令执行周期看指令设计涉及的问题
从存储器取指令:指令地址、指令长度(定长/变长)
对指令译码,以确定将要做什么操作:指令格式、操作码编码、操作数类型
计算操作数地址并取操作数:地址码、寻址方式、操作数格式和存放方式
进行相应计算,并得到标志位:操作类型、标志或条件码
将计算结果保存到目的地:结果数据位置(目的操作数)
计算下条指令地址(通常和取指令同时进行):下条指令地址(顺序/转移)
设计指令系统的核心问题,集中体现在指令的格式、寻址方式、功能类型 :

5.2 指令的格式
一条指令就是机器语言的一个语句,它是一组有意义的二进制代码。
一条指令通常要包括操作码字段和地址码字段两部分:
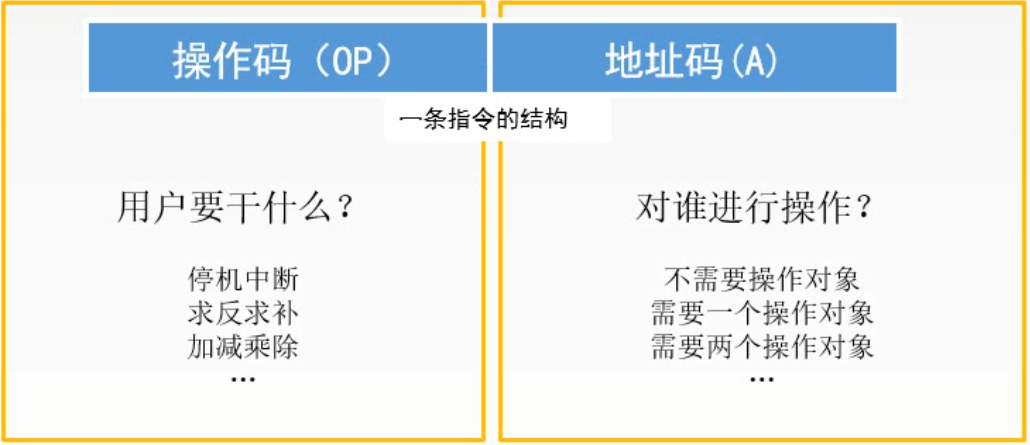
指令含义:(A1)OP(A2)→A3 , A4 => 下一条将要执行指令的地址
A1 A2 A3 代表地址, 加上( ) 就是取出这个地址当中的数值

当代计算机体系结构的形式,是冯.诺依曼等人提出的计算机设计的一些基本思想。
冯.诺依曼体制特点:
- 指令和数据均用二进制表示。
- 根本特征是采用存储程序原理,
基本工作方式是控制流驱动方式。
按地址访问并顺序执行指令。 - 计算机系统由运算器、
控制器、存储器、输入设备、输出设备
五大部件组成,并以运算器为核心的集中式控制。 - 指令由操作码和地址码组成。
指令在计算机中是顺序执行的,并受控制器的统一控制。
指令格式的选择应遵循的几条基本原则:
- 应尽量短
- 要有足够的操作码位数
- 指令编码必须有唯一的解释,否则是不合法的指令
- 指令字长应是字节的整数倍
- 合理地选择地址字段的个数
- 指令尽量规整
地址码编码原则:
- 指令地址码尽量短:目标代码短,省空间
- 操作数存放位置灵活,空间应尽量大:
- 有利于编译器优化产生高效代码
- 有效地址计算过程尽量简单:指令执行快
5.2.1 地址码结构
根据一条指令中有几个操作数地址,可将该指令称为几操作数指令或几地址指令。
- 三地址指令:第一操作数,第二操作数,结果地址(a+b=c;)
- 二地址指令:第一操作数,第二操作数,结果存在第一操作数下(a+=b;),按照操作数的物理位置不同分为:
- RR:寄存器-寄存器类型
- RS:寄存器-存储器类型
- SS:存储器-存储器类型
- 单地址指令:第一操作数(a++;)
- 零地址指令:如停机、清除等控制指令
5.2.1 操作码结构
设计计算机时,对指令系统的每一条指令都要规定一个操作码。指令的操作码OP表示该指令应进行什么性质的操作。不同的指令用操作码字段的不同编码来表示,每一种编码代表一种指令。组成操作码字段的位数一般取决于计算机指令系统的规模。较大的指令系统就需要更多的位数来表示每条特定的指令,按照操作码长度分为:
定长操作码:在指令字的最高位部分分配固定的若干位(定长)表示操作码。
- 一般位操作码字段的指令系统最大能够表示2”条指令。
优:定长操作码对于简化计算机硬件设计,提高指令译码和识别速度很有利: - 缺:指令数量增加时会占用更多固定位,留给表示操作数地址的位数受限。
扩展操作码(不定长操作码):全部指令的操作码字段的位数不固定,且分散地放在指令字的不同位置上。
- 最常见的变长操作码方法是扩展操作码,使操作码的长度随地址码的减少而增加,不同地址数的
指令可以具有不同长度的操作码,从而在满足需要的前提下,有效地缩短指令字长。 - 优:在指令字长有限的前提下仍保持比较丰富的指令种类:
- 缺:增加了指令译码和分析的难度,使控制器的设计复杂化。
- 等长:指令规整,译码简单,固定长度编码的主要缺点是:信息的冗余极大,使程序的总长度增加。
- 扩展操作码:指令不规整,译码复杂,效率高 => 一般用在指令长度比较短的机器上

定长指令字结构:指令长度固定
变长指令字结构:指令长度不等
扩展操作码举例
指令字长为16位:
前4位为基本操作码字段OP , 另有3个4位长的地址字段A1、A2和A3。
4位基本操作码若全部用于三地址指令,则有16条。
但至少须将1111留作扩展操作码之用,即三地址指令为15条;
11111111留作扩展操作码之用,二地址指令为15条;
111111111111留作扩展操作码之用,一地址指令为15条:
零地址指令为16条。

注意点
- 不允许短码是长码的前缀,即短操作码不能与长操作码的前面部分的代码相同。
- 各指令的操作码一定不能重复。
通常情况下,对使用频率较高的指令,分配较短的操作码;
对使用频率较低的指令,分配较长的操作码,从而尽可能减少指令译码和分析的时间。
对于上面 1111的状态, 有时可以不只是一个 , 可以有多个码来 表示多种状态

总结起来就是上面的少出去的是因为要用来扩展下一层
5.2.1 操作类型
- 简单了解即可

5.3 指令寻址

5.3.1编址
先来回顾一下数据存储相关的知识

按字节编址:每个字节存储单元都有一个地址编号
按字节地址寻址:给出一个字节地址,可以取出长度为一个字节的数据
按字地址寻址:给出一个字地址,可以取出长度为一个字的数据
比如下面的结构

那么子地址就是
0一3为一个字,4一7为一个字
每个字中最小的字节地址作为字地址
那么上图就可以 变为 :

那么假设此时 某数据长度为4B , 那么需要给出一个字地址 ( 字节的地址 )
假设此时的数据为12345678H (十六进制的数字) , 此时存放数据有大端小端的区分
大端: 把数据的高位放到 字节的低地址
小端: 把数据的高位放到 字节的高地址

地址的高低区分在于编号 , 也就是大小 ,
字长
- 机器字长:CPU一次能处理的二进制数据的位数。
- 存储字长:一个存储单元存储二进制代码的长度。 (大部分时候是指 一个存储字 所能存储的01 的位数 , 比如上图就是 32位 => 一个字节对应 8bit , 4*8=32 )
- 指令字长:一个指令字中包含二进制代码的位数。 => 我们都知道指令是由 01 构成的, 那么 01 的位数就是指令的字长
上面三个没有必然的关系, 但是三者的长度都是字节的整数倍
- 一个字节存储8位无符号数,储存的数值范围为0-255。如同字元一样,字节型态的变数只需要用一个位元组(8位元)的内存空间储存 -----百度百科
单字长指令 : 指令长度 = 机器字长
那么可以得到 :
- 双字长指令 : 指令长度 = 机器字长 *2
- 半字长指令 : 指令长度 = 机器字长 /2
这是由于早期在制造机器的时候一般会 使得 机器字长与 存储字长相同, 使得速度更快
边界对齐存储
顾名思义 , 就是存储的时候数据与 存储单元是否对齐
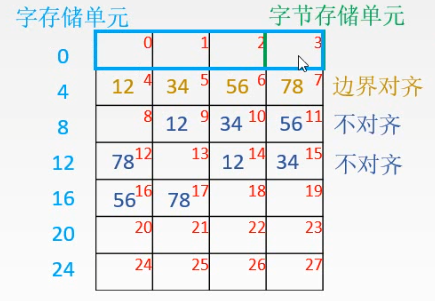
不对齐会影响机器的性能
对于 中间的数据 , 如果是对齐的 , 那么这个数据的字地址 一定是数据字节长度的整数倍
5.3.2寻址
寻址方式
- 指令寻址 : 定位下一条将要执行的指令 的 指令地址 => 始终由程序计数器PC给出
- 数据寻址 : 确定 本条指令的 操作数据的地址
1.指令寻址
顺序寻址
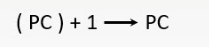
通过程序计数器PC加1(1个指令字长),自动形成下一条指令的地址。
跳跃寻址
通过转移类指令实现。
所谓跳跃,是指下条指令的地址不由程序计数器PC自动给出,
而由本条指令给出下条指令地址的计算方式。而是否跳跃可能受到状态寄存器和操作数的控制,
跳跃的地址分为绝对地址(由标记符直接得到)和相对地址(相对于当前指令地址的偏移量),跳跃的结果是当前指令修改PC值,所以下一条指令仍然通过PC给出
2.1数据寻址
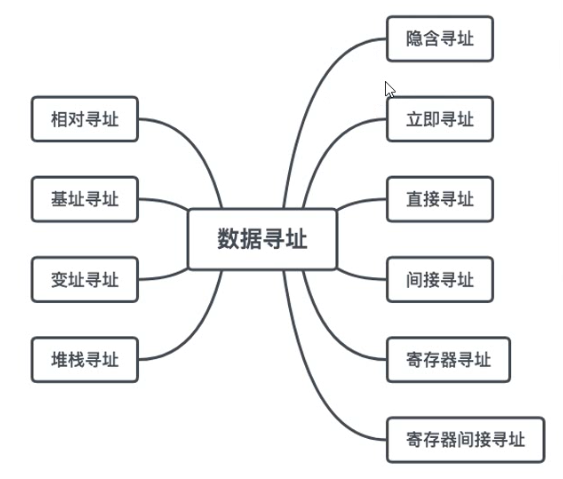
数据寻址是指如何在指令中表示一个操作数的地址,如何用这种表示得到操作数或怎样计算出操作数的地址。

数据寻址的方式较多,为区别各种方式,通常在指令字中设一个字段,用来指明属于哪种寻址方式,
由此可得指令的格式如下所示:

通过 寻址特征以及 形式地址 A 求出操作数的真实地址, 称为有效地址(EA)
上面的图示是一条一地址指令
多地址指令的示意图如下:

现在我们假设指令字长= 机器字长 = 存储字长
方便下面举例来学习数据寻址
假设操作数为3

1️⃣立即寻址: 形式地址A就是操作数本身,又称为立即数,一般采用补码形式。 # 表示立即寻址特征。
上面的 # 时给人看 的 , 实际在机器里面一般是 01代码
一条指令的执行 :
取指令访存1次
执行指令访存0次
暂不考虑存结果
共访存1次
优点:指令执行阶段不访问主存,指令执行时间最短
缺点:A的位数限制了立即数的范围。
- 如A的位数为n,且立即数采用补码时,可表示的数据范围为-2n-1~2n-1-1
2️⃣直接寻址:指令字中的形式地址A就是操作数的真实地址EA,即EA=A。
- 有效地址就是形式地址

LDA的作用就是把A 中的数据 取到ACC中
一条指令的执行:
取指令访存1次
执行指令访存1次
暂不考虑结果
共访存2次
优点:简单,指令执行阶段仅访问一次主存,不需专门计算操作数的地址。
缺点:A的位数决定了该指令操作数的寻址范围。操作数的地址不易修改。
3️⃣间接寻址 : 指令的地址字段给出的形式地址不是操作数的真正地址,
而是操作数有效地址所在的存储单元的地址,也就是操作数地址的地址,即EA=(A)。
A表示地址, (A) 表示取出A地址存放的数据
- 就是修改了 数据存放的地址


可以理解为就是通过藏宝图去寻找宝藏, 如果是多次间接寻址 , 那么就是多步的藏宝图
一条指令的执行:
取指令访存1次
执行指令访存2次
暂不考虑存结果
共访存3次
优点:可扩大寻址范围(有效地址EA的位数大于形式地址A的位数)。便于编制程序(用间接寻址可以方便地完成子程序返回)。
缺点:指令在执行阶段要多次访存(一次间址需两次访存,多次寻址需根据存储字的最高位确定几次访存)。
4️⃣寄存器寻址:在指令字中直接给出操作数所在的寄存器编号,即EA=Ri,其操作数在由Ri所指的寄存器内。
- 模式跟直接寻址是一样的, 不过把主存换乘了寄存器
- 由于寄存器的数量较少 , 因此这个Ri实际上是比较短的 ( 指令字短 ) , 比较节省空间
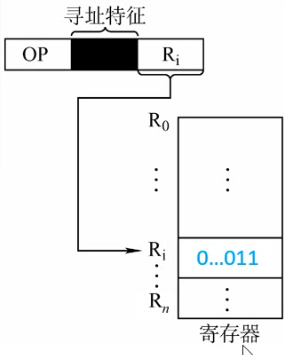
一条指令的执行:
取指令访存1次
执行指令访0次
暂不考虑存结果
共访存1次
优点:指令在执行阶段不访问主存,只访问寄存器,指令字短且执行速度快,支持向量/矩阵运算。
缺点:寄存器价格昂贵,计算机中寄存器个数有限。
5️⃣寄存器间接寻址 : 寄存器Ri中给出的不是一个操作数,而是操作数所在主存单元的地址,即EA=(Ri)。
(Ri) 表示取出 Ri 存放的 值, 那么的当前的情况 , Ri存放的是数据的地址 => 指向存储单元中的内容
- 其实跟间接寻址差不多, 不过吧主存换乘了寄存器

一条指令的执行:
取指令访存1次
执行指令访存1次
暂不考虑存结果
共访存2次
特点:与一般间接寻址相比速度更快,但指令的执行阶段需要访问主存(因为操作数在主存中)。
慢于寄存器寻址
6️⃣隐含寻址:不是明显地给出操作数的地址,而是在指令中隐含着操作数的地址。
ACC : 累加寄存器
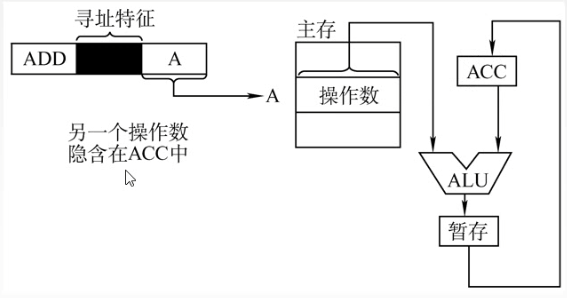
优点:有利于缩短指令字长。
缺点:需增加存储操作数或隐含地址的硬件。
那么来总结对比以上六种数据寻址方式

2.2数据寻址–偏移寻址

7️⃣基址寻址:将CPU中基址寄存器(BR)的内容加上指令格式中的形式地址A, 而形成操作数的有效地址,
- 即EA=(BR)+A。
采用专用寄存器作基址寄存器(隐式寻址):
计算机内专门设有一个基址寄存器BR,用户使用时不用明显指出该基址寄存器,只要由指令的寻址特征位反映出基址寻址即可。

BR 为基址寄存器,,A为偏移量,实际有效地址为基址+偏移量,可扩大寻址范围,BR 内容由操作系统或管理程序确定,在程序的执行过程中 BR 内容不变,形式地址 A 可变。用户不必考虑自己的程序存在于主存的那个空间区域,
当采用通用寄存器作为基址寄存器时,可由用户决定哪个寄存器作为基址寄存器,
但其内容仍由操作系统确定。有利于多道程序设计。
为什么利于多道程序设计
- 用户无需考虑程序存放在主存中的哪里,只要指出哪个寄存器作为某个程序的基址寄存器即可,由操作系统或管理程序自动分配。分别用不同的寄存器表示多道程序的基址寄存器,程序执行时用户不知道程序在主存中的位置,也不可修改基址寄存器的内容,确保系统安全可靠地运行。
- 可扩大寻址范围(基址寄存器的位数大于形式地址A的位数);用户不必考虑自
己的程序存于主存的哪一空间区域,故有利于多道程序设计,以及可用于编制浮动程序。
采用通用寄存器作基址寄存器:
在一组通用寄存器中,由用户指出哪个寄存器用来作为基址寄存器。

注:基址寄存器是面向操作系统的,其内容由操作系统或管理程序确定。在程序执行
过程中,基址寄存器的内容不变(作为基地址),形式地址可变(作为偏移量)。
8️⃣变址寻址:有效地址EA等于指令字中的形式地址A与变址寄存器X的内容相加之和,
即EA=(X)+A,其中IX为变址寄存器(专用),也可用通用寄存器作为变址寄存器。
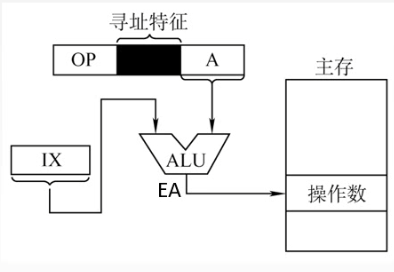
注:变址寄存器是面向用户的,在程序执行过程中,变址寄存器的内容可由用户改变
(作为偏移量),形式地址A不变(作为基地址)。
优点:可扩大寻址范围(变址寄存器的位数大于形式地址A的位数);在数组处理过程中,
可设定A为数组的首地址,不断改变变址寄存器X的内容,便可很容易形成数组中任一数据的地址,
特别适合编制循环程序。
举例 => 帮助理解
右边方框里面的都是 汇编指令

更多时候我们是结合多种寻址方式来使用:
- 变址寻址与基址寻址配合使用:EA=A+(BR)+(IX)
- 变址寻找与间接寻址配合使用:
如先变址后间址,EA=(A+(IX));
先间址后变址,EA=(A)+(IX)。
9️⃣相对寻址 : 把程序计数器PC的内容加上指令格式中的形式地址A而形成操作数的有效地址,
即EA=(PC)+A,其中A是相对于当前指令地址的位移量,可正可负,补码表示。

优点:操作数的地址不是固定的,它随着PC值的变化而变化,并且与指令地址之间总是相差一个固定值,因此便于程序浮动。
相对寻址广泛应用于转移指令。
注意与基址寻址的区别
2.3数据寻址–堆栈寻址
- 不是特别重要
之前的九种寻址方式其实都涉及到一个形式地址的转换的问题
堆栈寻址:操作数存放在堆栈中,隐含使用堆栈指针(SP)作为操作数地址。
堆栈是存储器(或专用寄存器组)中一块特定的、按后进先出(LFO)原则管理的存储区,该存储区中读/写单元的地址是用一个特定的寄存器给出的,该寄存器称为堆栈指针(SP)。堆栈可分为硬堆栈与软堆栈两种。

大致流程


5.4 CISC与RISC

CISC
- Complex Instruction Set Computer
设计思路:一条指令完成一个复杂的基本功能。
代表:x86架构,主要用于笔记本、台式机等
RISC
- Reduced Instruction Set Computer
设计思路:一条指令完成一个基本“动作”;多条指令组合完成一个复杂的基本功能。
代表:ARM架构,主要用于手机、平板等
比如设计一套能输出单词的指令集:
CISC的思路:每个单词的输出由一条指令完成
一条指令可以由一个专门的电路完成:
17万个单词=17万个电路
→采用“存储程序”的设计思想,由一个比较通用的电路配合存储部件完成一条指令
RISC的思路:每个字母的输出由一条指令完成,
多条指令组合完成一个单词
=> 26个字母=26个电路
对比